什么是RAG-Cloudflare
检索增强生成(RAG)是一种将您自己的数据与大型语言模型(LLM)结合使用的方法。RAG 不仅依赖于模型训练时的数据,而是从您的数据源中搜索相关信息,并利用这些信息来帮助回答问题。
RAG 的工作原理
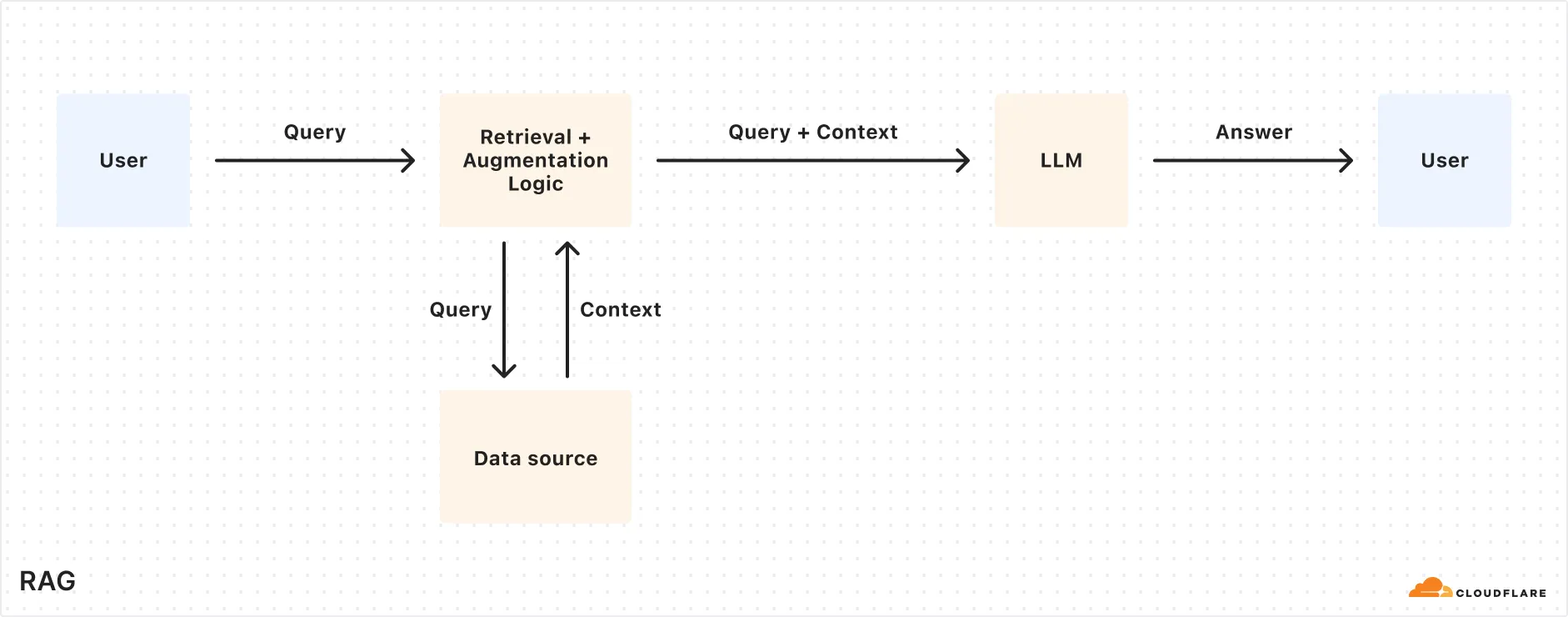
以下是 RAG 流程的简化概述:
- 索引: 您的内容(例如文档、维基、产品信息)被拆分成较小的块,并使用嵌入模型转换为向量。这些向量存储在向量数据库中。
- 检索: 当用户提出问题时,该问题也会被嵌入到一个向量中,并用于从向量数据库中找到最相关的片段。
- 生成: 检索到的内容和用户的原始问题被组合成一个单一的提示。一个 LLM 使用该提示生成响应。
生成的响应应该是准确的、相关的,并基于您自己的数据。
为什么使用 RAG?
RAG 允许您在 LLM 生成中引入自己的数据,而无需重新训练或微调模型。它通过在查询时检索相关内容并将其作为响应的基础,从而提高了准确性和可信度。
使用 RAG 的好处:
- 准确和最新的答案: 回复基于您最新的内容,而不是过时的训练数据。
- 对信息来源的控制: 您定义知识库,因此答案来自您信任的内容。
- 更少的幻觉: 回复基于真实的、检索到的数据,减少虚构或误导性的答案。
- 无需模型训练: 您可以获得高质量的结果,而无需构建或微调自己的 LLM,这可能耗时且成本高昂。
RAG 非常适合构建以下类型的 AI 驱动应用:
- 用于内部知识的 AI 助手
- 连接到您最新内容的支持聊天机器人
- 跨文档和文件的企业搜索