检索增强生成-LangChain
概述
检索增强生成(RAG)是一种强大的技术,通过将其与外部知识库结合,增强了 语言模型 。RAG 解决了 模型的一个关键限制 :模型依赖于固定的训练数据集,这可能导致信息过时或不完整。当给定一个查询时,RAG 系统首先在知识库中搜索相关信息。然后,系统将检索到的信息纳入模型的提示中。模型利用提供的上下文生成对查询的响应。通过弥合庞大的语言模型与动态、针对性的信息检索之间的差距,RAG 成为构建更强大和可靠的人工智能系统的强大技术。
关键概念
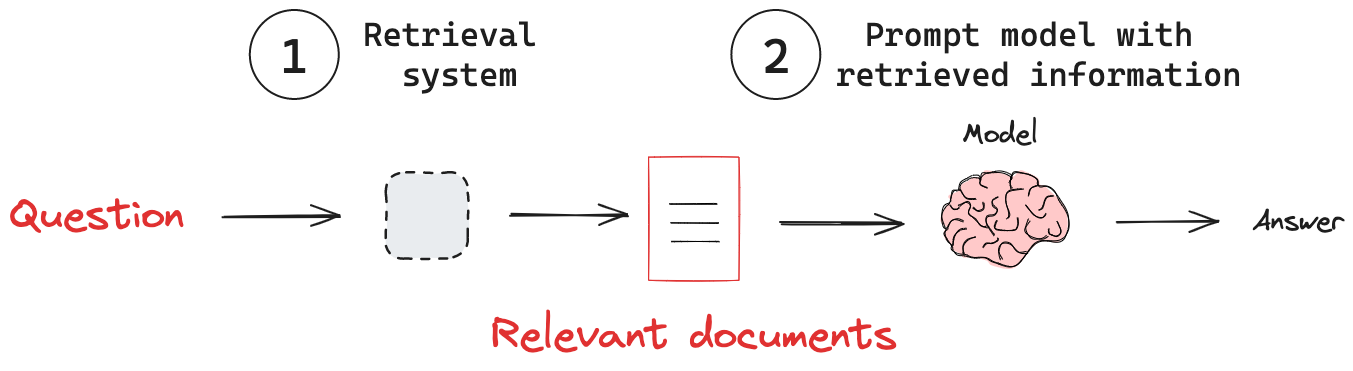
(1) 检索系统 : 从知识库中检索相关信息。
(2) 添加外部知识 : 将检索到的信息传递给模型。
检索系统
模型的内部知识通常是固定的,或者至少由于训练成本高而不经常更新。这限制了它们回答当前事件问题或提供特定领域知识的能力。为了解决这个问题,有各种知识注入技术,如 微调 或持续预训练。这两者都是 昂贵的 ,并且通常 不适合 事实检索。使用检索系统提供了几个优势:
- 最新信息 :RAG 可以访问和利用最新数据,使得响应保持最新。
- 特定领域的专业知识 :通过特定领域的知识库,RAG 可以在特定领域提供答案。
- 减少幻觉 :将响应基于检索到的事实有助于最小化虚假或虚构的信息。
- 经济高效的知识整合 :RAG 提供了一种比昂贵的模型微调更高效的替代方案。
添加外部知识
有了检索系统,我们需要将该系统中的知识传递给模型。RAG 流水线通常通过以下步骤实现这一目标:
- 接收输入查询。
- 使用检索系统根据查询搜索相关信息。
- 将检索到的信息纳入发送给 LLM 的提示中。
- 生成一个利用检索到的上下文的响应。
作为一个例子,这里有一个简单的 RAG 工作流程,它将信息从一个 检索器 传递给一个 聊天模型 :
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
# Define a system prompt that tells the model how to use the retrieved context
system_prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Context: {context}:"""
# Define a question
question = """What are the main components of an LLM-powered autonomous agent system?"""
# Retrieve relevant documents
docs = retriever.invoke(question)
# Combine the documents into a single string
docs_text = "".join(d.page_content for d in docs)
# Populate the system prompt with the retrieved context
system_prompt_fmt = system_prompt.format(context=docs_text)
# Create a model
model = ChatOpenAI(model="gpt-4o", temperature=0)
# Generate a response
questions = model.invoke([SystemMessage(content=system_prompt_fmt),
HumanMessage(content=question)])